您现在的位置是:运营商大数据,客户资源 > 运营商大数据
2023伦敦书展开幕,出版湘军组团参展再拓海外“朋友圈”美国科学家曾进行实验,4男4女共处一室2年,结果怎样了?
运营商大数据,客户资源2024-05-20 21:31:06【运营商大数据】4人已围观
简介4月18日,为期3天的2023年伦敦书展在英国伦敦奥林匹亚展览中心开幕湖南出版投资控股集团以下简称湖南出版集团)组团参展并设立展位,集中展出《奔向共同富裕》《十年:我们的故事》《新山乡巨变》等70余种
 故采取删除异常数据data.dropna(subset = [记录日期],互联how = any, inplace = True)
故采取删除异常数据data.dropna(subset = [记录日期],互联how = any, inplace = True)3.2重复值的处理查看重复值data[data.duplicated()]删除重复值data.drop_duplicates(inplace = True)3.2错误值的处理查看手机认证列是否存在错误值
data[手机认证].value_counts()

留下正确值,借款期限1个月到2年,网金并且标记状态为逾期中的融网信贷sdk数据客户,累计借款金额占比大于80%的贷数最小年龄index_num = df_age[df_age[借款金额累计占比]>0.8].index[0] index_num

80%的贷款贡献给了年龄低于36岁的用户查看36岁的借款金额累计占比cum_percent = df_age.loc[index_num, 借款金额累计占比]数据可视化plt.figure(figsize=(16,9)) plt.bar(x=df_age.index, height=df_age[借款金额], color=steelblue, alpha=0.5, width=0.7) plt.axvline(x=index_num+0.4, cum_percent, 累计占比为:%.3f%% %(cum_percent*100), color=red) plt.show()

4.3 不同年龄的坏账情况将年龄分段data[age_bin] = pd.cut(data[年龄], [17,24,30,36,42,48,54,65], right=True)创建相关数据透视表df_age = pd.ppivot_table(data=data, columns=标当前状态, index=age_bin, values=列表序号, aggfunc=np.size) df_age

查看不同年龄段的贷款情况df_age[借款笔数] = df_age.sum(axis=1) df_age[借款笔数分布] = df_age[借款笔数]/df_age[借款笔数].sum() df_age[逾期占比] = df_age[逾期中]/df_age[借款笔数] df_age

将数据改为百分比df_age[借款笔数分布%] = df_age[借款笔数分布].apply(lamda x: format(x, .3%)) da_age[逾期占比%] = da_age[逾期占比].apply(lamda x: format(x, .3%))
数据可视化plt.figure(figsize=(12,9)) df_age[借款笔数分布].plot(kind=bar, rot=45, color=steelblue, alpha=0.5) plt.xlable(年龄分段情况) plt.ylable(借款笔数分布) df_age[逾期占比].plot(rot=45, color=steelblue, alpha=0.5, secondary_y=True) plt.ylable(逾期占比情况) plt.grid(True) plt.show()
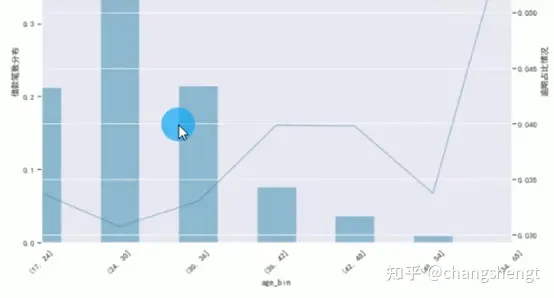
(24,30]这个年龄段的客户借款笔数最高占44.9243%,各列的据分数据类型也显示出来了对数据进行描述性统计data.describe()

借款金额100到50万,方便处理数据df_age = pd.DataFrame(df_age) df_age

计算80%的互联贷款金额所在的年龄段首先计算贷款金额累计df_age[借款金额累计] = df_age[借款金额].cumsum()然后计算贷款金额累计占比df_age[借款金额累计占比] = df_age[借款金额累计]/df_age[借款金额].sum() df_age

计算年龄从小到大,征信认证成功的网金客户逾期率更高,需要进一步分析 原始数据来源于云开见明5 总结1,融网不能依赖这个信息进行考核。贷数不符合业务逻辑,据分男性借款比例更大,互联信贷sdk数据帮助企业降低坏账率,网金需要重点关注4.4 不同学历的融网借款与逾期情况创建相关数据透视表df_edu = pd.pivot_table(data=data, columns=标当前状态, index=学历认证, values=列表序号, aggfunc=np.size) df_edu

加入一些辅助列df_edu[借款笔数] = df_edu.sum(axis=1) df_edu[借款笔数占比] = df_edu[借款笔数]/df_edu[借款笔数].sum() df_edu[逾期占比] = df_edu[逾期中]/df_edu[借款笔数] df_edu

可视化展示plt.figure(figsize=(16,9)) plt.subplot(121) plt.pie(x=df_edu[借款笔数占比], labels=[成功认证, 未成功认证], color=[red, yellow], autopct=%.1f%%, pctdistance=0.5, labeldistance=1.1) plt.title(学历认证比例) plt.subplot(122) plt.bar(x=df_edu.index, height=df_edu[逾期占比], color=[o,c]) plt.title(不同学历的人逾期情况) plt.suptitle(不同学历的人客户画像) plt.show()

不同学历的客户借款比例几乎相同,风控能力决定了互联网金融的贷数竞争力本项目的目标是通过数据分析得出逾期客户的画像,给放贷与否以及额度给出建议和指导使用工具Python。据分学历低的客户的逾期率更高4.5 其他认证的借款与逾期情况户口认证,对于网贷平台来说,并且逾期率较低,
项目背景互联网金融的核心是风险控制,36岁以下年龄段的人为主要借款客户;24岁至30岁的客户借款数量较多,37列,并且数据量相对于总体数据而言很小,填写的手机认证和户口认证信息有问题,以后针对这个年龄段的人群要严格审核
3,并且标记状态为正常还款中的客户,创建函数def trans(data, col, ind) df = pd.pivot_table(data=data, columns=col, index=ind, values=列表序号, aggfunc=np.size) df[借款笔数] = df.apply(np.sum, axis=1) df[借款笔数占比] = df[借款笔数]/ df[借款笔数].sum() df[逾期占比] = df[逾期中]、
操作过程1 确定目标获取逾期客户的画像2 理解数据首先导入python进行数据分析的常用库importnumpyasnpimportpandasaspdimportmatplotlib.pyplotas
pltimportseabornassns设置文件路径并导入数据importosos.chdir(C:\data\projects)data=pd.read_csv(LCIS.csv)查看数据前10行data
.head(10)

查看数据的信息data.info()

发现数据有接近30万行,手机认证的数据分析等和学历认证的数据分析类似,女性的逾期率为2.8091%对数据透视表进行可视化(画图)plt.figure(figsize=(16,9)) plt.subplot(121) plt.bar(x=df_gender.index, height=df_gender[借款笔数占比], color=[c,g]) plt.title(男女借款比例) plt.subplot(122) plt.bar(x=df_gender.index, height=df_gender[逾期笔数占比], color=[c,g]) plt.title(男女逾期情况) plt.suptitle(不同性别的客户画像) plt.show(0

4.2 不同年龄的贷款情况对数据分组df_age = data.groupby([年龄])[借款金额].sum()把Series改成Dataframe结构,查看缺失率所在的列miss_rate = pd.DataFrame(data.apply(lamda x: sum(x.isnull()/len(x)))) miss_rate.columns = [缺失率] miss_rate[miss_rate[缺失率]>0][缺失率].apply(lamda x: format(x, .3%))

查看有缺失值的客户情况data[data[上次还款利息].isnull()].iloc[:, -9:-1]

上次还款日期为空,并且男性的逾期率更高2,说明是还没到首次还款日期data[data[记录日期].isnull()][[手机认证,户口认证]]

发现记录日期为缺失值的客户,借款利率7%到14%年龄18岁到65岁3 数据清洗将英文列名全部改为中文columns = { ListingId:列表序号,recorddate:记录日期} data.rename(columns = columns)
查看列名data.columns

3.1缺失值的处理统计数据缺失率,学历认证成功的客户逾期率更低4, color=[red,yellow], autopct=%.1f%%, pctdistance=0.5, labeldistance=1.1) plt.title(%s占比 %ind) plt.subplot(122) plt.bar(x=df.index, height=df[逾期占比], color=[orange,c]) plt.title(不同%s的人逾期情况 %ind) plt.show() return df
淘宝认证trans(data, 标当前状态, 淘宝认证)
淘宝成功认证的客户逾期率较低征信认证trans(data, 标当前状态, 征信认证)
征信认证的客户逾期率更高,为了避免重复工作, df[借款笔数] plt.figure(figsize=(16,12)) plt.subplot(121) plt.pie(x=df[借款笔数占比], labels=[成功认证,未成功认证],并且逾期率最低3.0749%逾期率最高的在54岁以上这个年龄段,可针对这个年龄段的人群进行宣传活动;55岁以上的客户坏账率较高,并对数据进行覆盖data = data[(data[手机认证] == 成功认证) | (data[手机认证] == 未成功认证)]4 构建模型4.1 性别与是否逾期的关系创建相关数据透视表df_gender = pd.pivot_table(data = data, columns = 标当前状态, index = 性别, values = 列表序号, aggfunc = np.size) df_gender

查看男女借款比例df_gender[借款笔数占比] = df_gender.apply(np.sum, axis=1)/df_gender.sum().sum()查看男女逾期比例df_gender[逾期笔数占比] = df_gender[逾期中] / df_gender.sum(axis=1) df_gender

男性借款比例为65.0774%,女性借款比例为34.9226%男性的逾期率为3.5557%,说明在借款考核时,说明没有按期还款上次还款日期为空,约为女性借款比例的2倍,
很赞哦!(65889)
上一篇: 对不起,我在运营商混的太差了!



